
Updated April 1st, 2024 — version 338
The UnFair Advantage Book
Winning the Search Engine Wars
 Chapter Three
Chapter Three
The Various Types of Search Results & Where They Come From
When generating search results, search engines make use of many sources of information which include, but are not limited to, webpages, images, shopping, news, maps, and videos. This is often referred to as Universal Search.
High ranking success is dependent on learning where the search results are coming from so you can position your content accordingly. Keep in mind there are many different paths to the top of the unpaid-for (organic) search results.
For instance, some search results are heavily influenced by Personalization. This means the results YOU see from your east coast city location might not be the same results that your friend in Seattle sees for the same search. That's because personalized search results can vary according to:
- Reported Location
- IP Location
- GPS Location (Mobile)
- Search History (signed-in / cookies)
- Social Networks (Likes / Friends / Circles)
- Device (Mobile / TV / Desktop)
- Language
- Previous Searches
Notice that the first three determinants on the list are location, location, and location. First and foremost, Google wants to know your location.
After that it's your recent search history followed by the rest of the factors on the list. You should expect each of the above personalized elements to significantly affect your search results.
Most search queries generate results from many different sources. Such Universal search results are pulled from website images, YouTube videos, recent news stories, Twitter, Facebook, Pinterest, Wikipedia, and so forth.
In the screenshot below we see our search for BMW generated an AdWords (paid) result and a Knowledge Box on the right side panel. The Knowledge Box pulled general information from Wikipedia and BMW stock price info scraped from website sources like Morningstar, Refinitiv, and ICE Data Services. Below that the knowledge box provides links to more related Google search results.

As you may have already noticed, the "above-the-fold" (i.e., prior to scrolling) search results are where the paid Ads and information resources appear. Notice that the organic listing that appears below the Ad points to the same URL as the Ad seen above it. This is often the case for branded searches.
If we scroll down "below-the-fold" on that same results page, we get a map and local search results for the New York City area. These geolocation results are based on Google's detection of our IP address which indicates we are searching from a location in or near New Your City. These are unpaid-for (organic) local search results, not Ads, and the searcher can tap the View All button at the bottom for more results like this.

On the right side panel in the image above, where the red hand points to a pull-down toggle labeled Slogan, Google provides a snippet pulled from the website — hotcars.com — regarding "The Secret Origin Of BMW's 'Ultimate Driving Machine' Slogan". The searcher gains info on the topic without having to leave Google's site. A link is provided to the source if the searcher wants to learn more. Again, this is an organic result, not a paid Ad.
Lower down, the BMW car images are links that connect to more related searches. Continuing down the right side panel we find links to BMW's social media pages and then we find a People also searched for related Google searches – all of these related search links keep the searcher on Google's site and each of them leads to a search results page with at least one Ad at the top.
In the next image, as we scroll down the first page of the search results, we see two organic listings and then Top Stories. This is the latest news related to our search term – BMW — followed by another organic search result.

Remember, we are still scrolling down the first page of the search results for BMW. Next we see images that Google pulls from various sites online. Once again, these image results are organic, unpaid-for search results. Next we find results pulled from Twitter — in this case, from BMW's Twitter account.

And finally, as we finish scrolling down the first page of the search results, we see another organic search listing followed by BMW related videos pulled from YouTube.

Notice at the bottom of the page, the geolocation note saying: New York - Based on your past activity. Tap the tiny dot alongside the location, in this case New York, and you'll get a pop-up box that says...

Just to be clear, Google doesn't always tell the whole story in regards to how exactly they determine your location. Past activity is certainly a determinant, as is whatever they know about you if you are logged in.
However in the case of the BMW search result we've been using as an example, Google originally inferred our location based on the IP address they detected when we began searching from a New York City IP address location. Then after a few searches, our "past activity" became the location determinant.
However, the next morning when we switched our IP location to Seattle, and changed nothing else, the BMW search gave us results for Seattle as seen below in the split screen which also claims the search results were based on "past activity" ...
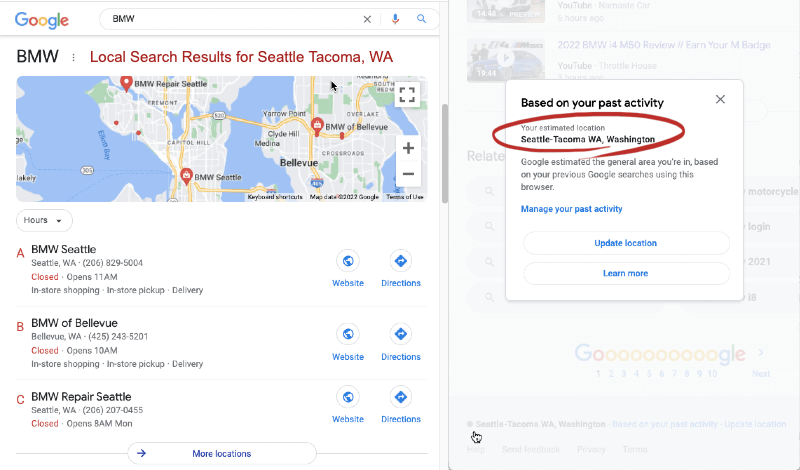
But, in fact the results were based solely on IP address location.
Then a few minutes later, after clearing our cache of Google's cookies, we logged into a Dallas IP location and Google gave us the following Dallas area results...

As you can see, this time Google tells us the IP address was being used to determine our location.
That's because they had no "past activity" to base our search on. Since we cleared all of Google's cookies from our cache, they had only the IP address available to use as the location determinant.
By the way, if Google asks for your location you don't have to choose between blocking it or allowing it. You can simply close the query box by tapping the X...

When doing our research for SEO purposes, we find it useful to research and compare the results for various locations. But in fact, all of the searches in this book are actually being done from a location in Hawaii. As you might guess, the clients we work with are rarely-if-ever in Hawaii — so using our actual location would provide non-relevant results for our clients' target markets.
As such, you too may also find it useful to research locations far and away from your actual location. So, knowing this "trick" can come in handy.
Most importantly, you need to know that Google's search results are HIGHLY geotargeted. Depending on your "location" the search results can vary dramatically from city to city, region to region, and country to country.
Beyond location,
- personalization,
- browser history,
- and search history,
...are what determine the search results that Google serves you and everyone else searching for anything anywhere in the world.
Therefore, we recommend that you...
never do SEO research while logged into your personal Google account.
Doing so will dramatically skew your results. That's because those results will be personalized only to you. That makes it unlikely that you're seeing the results as others are seeing them.
And, as you've seen, having the ability to change your IP location is also useful. For that we use a VPN — a virtual private network. Here's the one we use: Express VPN (if you join using that link we'll get a free month).
If you're looking for an ad blocker, we recommend uBlock Origin — it's free and works incredibly well, especially if used simultaneously with Privacy Badger (also free) made available by the non-profit, privacy defending Electric Frontier Foundation (EFF).
All of these tools can be toggled on or off and configured to activate, or not, on a site by site basis. They are super-helpful in identifying what-are-Ads and what-are-not. And you'll be absolutely amazed to see what the web looks like when you're browsing Ad-free.
Once you start using them you'll wonder why everyone isn't using them. And, yes, Google is scared shirtless, that everyone WILL start using them! ...just another reason for us online marketers to focus on ranking high in the organic side of the search results.
Moving on...
Our BMW search example shows what you would typically expect to see in Google's search results when doing a "brand" related search. As expected, the search results narrowly focused on everything BMW – Ads, news, social, video, and organic — all focused on the brand of a single company known for that particular brand name.
Switching gears, you might remember back in Chapter Two we showed you a non-brand name search for best air conditioner which produced a carousel of paid ads served by AdWords at the top of the search results followed by the organic listings.
In the image below we did the same search twice — once logged into a Dallas - Ft Worth, TX and another while logged into a location near Seattle, WA.

As the image shows, we did these searches on March 20, 2022. Notice that the Dallas results show a carousel of paid Ads while the Seattle results show only organic search listings.
If you're wondering why no paid Ads for Seattle, check the weather report superimposed top-center over the results page.
If you guessed that nobody in Seattle is buying air conditioners on a rainy 53/41 degree day in March, you guessed right. So, what kind of fool would pay to advertise air conditioners to Seattleites at that time of the year?
In Dallas however, clear and 83 degrees is a different story. In fact the leading paid Ad in the carousel is for an A/C unit that retails for way-more than $10K! ...the next one is over $9K ...that's some serious air conditioning and it's apparent that the Dallas market is ready to beat the heat while the Seattle market is hoping it'll just stop raining.
The point is that, not only can search results vary due to inherent differences between locations, they can also vary between places due to a multitude of factors, not the least of which is weather.
It would be impossible to list all of the different scenarios and determinants that affect the search rankings from place to place and season to season but also in the minutia like time of day which can also significantly affect what you see in the search results.
In our example above, all of the organic listings are identical in both locations.
Scrolling down the results page, the image below shows the products carousel is next and it lists the same exact products in exactly the same order in both locations.
To reveal details about these product carousel results, we tap the three tiny dots indicated by the red arrow to get a pop-up information box About this result ...

According to About this result ...
This is info that Google gathered about products available to buy
This is a search result, not an ad. Only ads are paid, and they'll always be labeled with "Sponsored" or "Ad."
The listings in the product carousel are, as the info-box says, another form of unpaid-for search results. They include product names and part numbers and they are supplied to Google Shopping by advertisers via Google's Merchant Feed.
Next...
So far, except for the Ads carousel displayed on the Dallas search results page, the Seattle and Dallas organic and product feed listings have been the same.
But, when we scroll down to the local search results, once again we see a difference based on local weather.
Notice that the Dallas local results are Best Air Conditioners whereas it's still winter in Seattle (and a wet 41-low is colder than phuck) so, instead, we see listings for Hvac (heating, ventilation, air conditioning) Contractors ...

Different needs for different places — and Google is ALL about serving the needs of their searchers — locally (for fun and profit!). Amen.
Speaking of differences, the People Also Ask (PAA) feature, while found on both results pages, are located in different positions.
The Dallas PAA is located near the top of the results, just under the fold so that it's the first thing you see when you begin to scroll down.
The Seattle PAA is located at the bottom of the results page, just above the Related searches feature.

People in Dallas are starting to think, "omg, summer is coming" so they're, you know, asking A/C questions.
In Seattle, A/C related PAA questions are relegated to the bottom of the results page because Seattleites are only asking, "omg, when will winter be over?" — nobody in Seattle is thinking about A/C in March.
The last scroll on the first page produces YouTube video results that are identical in both locations. At the bottom of the results page, Related searches are almost identical (9 out of 10). That rounds out the first page of the best air conditioner search results.
The take-away here is that local variables are an important factor to consider when building your webpages. It's important to know...
- who's your target audience,
- what they're thinking
- and where they are located
...at the time that you are targeting them.
And remember, this is only one example. It's intended to help you identify the multiple opportunities for getting your pages, products, and services listed prominently in the various locations available in the unpaid-for (organic) search results.
Moving on...
Now that you've seen a branded search, and a product search, let's look at a non-commercially oriented type search.
These kinds of search results will differ yet again. Such categories can range all over the board with far, far, too many to list. But a few of them could be recipe searches, handicraft searches, fix-it searches, hobby searches — really, just about anything.
These searches might be academic, technical, medical, informational, etc., and usually non-commercial — at least on the surface. They might lead toward a later conversion or a membership or a subscription but they are mostly the kind of searches that return results which aren't usually accompanied by Ads.
With all that in mind, lets do a search for How to wire a light switch ...

As you can see, this "technical" search produces results that are focused on showing how to complete a DIY (do-it-yourself) task.
It's notable that YouTube video results appear first, above the organic results as a Featured Snippet. Also noteworthy is that every video includes a key moments timeline menu that enables viewers to go straight to the video segments that are of most interest.
If you are making videos to rank well in the search results, you would need to include this timeline menu feature to compete for top rankings.
Following the videos is an images carousel pulled from various websites with images that are relevant to this search.
The bottom section is the organic listings with descriptions and links to websites with content relevant to our search phrase (ie. keyword).
Between the image results and the organic search listings we see the People Also Asked (PAA) feature.
The image below shows what happens when we select the pull-down on PAA...

When we open the first PAA on the list, the info-box displays a YouTube video which is cued up to begin at the precise location in the video timeline that answers that specific question being featured in PAA.
Each time you tap a pull-down, PAA adds two more questions — and will do so almost endlessly for as long as you keep tapping the pull-down arrows.
As we'll show you later in Chapter Six, PAA is one of the many good places to do your keyword research. You can also use it for brainstorming ideas to help get your own website's pages featured in PAA.
In Summary
Now you know the content, source, and mix of Universal Search Results varies greatly depending on circumstances such as query, time, location, history, personalization, and so forth.
Furthermore, content that is fresh or topical — i.e., content that is currently popular or making headline news — will often rise temporarily to the top of the rankings and beat out webpages that would otherwise be ranked at the top by way of trust and authority. Such bias is referred to as Query Deserves Freshness (QDF).
Plus, in general searches where the search term can mean many different things, the search results will show a diversified mix of content. This bias toward what's known as Query Deserves Diversity (QDD) explains why a page with far less authority can rank well when it's relevant for an alternative meaning in a search.
And, if a search term matches a Trending Topic that's generating a spike in traffic, most engines will favor recent content over otherwise superior ranking webpages. Generally speaking, this places News Stories at the top of the listings.
So, as you are seeing,
Universal Search Results will include all of the following types of search results:
- Organic Listings
- Local Search
- News & Realtime
- Shopping
- Featured Snippets
- Knowledge Box
- Social
- Query Deserves Freshness
- Query Deserves Diversity
- Trending Topic
- Brand and Product Name
- Pay-Per-Click (i.e., AdWords)
...each being pulled from their respective sources and positioned on the search results page in their order of relevance to the search, the location, and the searcher.
Now it's time to learn the secrets to ranking your videos, images, and webpages at the top of the search results!